15分で作る、Logstash+Elasticsearchによるログ収集・解析環境
公開日
更新日

複数台のサーバーを運用している場合に、それらのログを集中管理したいというケースがある。この場合、ログを収集するためのサーバーを用意し、そこに各サーバーからログを送信して集中管理することになる。こういった環境を構築するためのツールとして近年注目されているのが、ログ管理ツール「Logstash」と、分散型データベース「Elasticsearch」の組み合わせだ。今回はこれらツールの概要と、これらを利用したログ収集環境の構築例を紹介する。
目次
「Elasticsearch」と「Logstash」、「Kibana」によるログ収集管理システム構築
クラウドサービスを使ってサーバーを運用している場合、サーバー上のストレージをいつ削除しても良いよう、ログデータは別サーバーに保存しておくことが多い。また、複数台のサーバーを用意して負荷分散を行っている場合などにそれらすべてのログをまとめて管理したい、といったケースもある。
こういった状況に向けて、ログを1つのサーバーに集約して管理するツールがいくつか開発されている。その1つが今回紹介する﹁Logstash﹂だ︵図1︶。Logstashはログの収集と記録のための機能を備えており、プラグイン形式で機能を拡張できるのが特徴の1つとなっている。
図1 LogstashのWebサイト
Logstashの構造
Logstashに限らず、多くのログ記録・管理ツールは記録すべき﹁イベント﹂を監視し、イベントが発生したらその情報を整形し、しかるべき場所に適切な形式で出力する、という機能を備えている。Logstashはこれらの処理をそれぞれ﹁input﹂および﹁filter﹂、﹁codec﹂、﹁output﹂と呼び、それぞれをプラグインとして実装することでさまざまなイベントや出力先に対応できるようになっている︵図2、表1︶。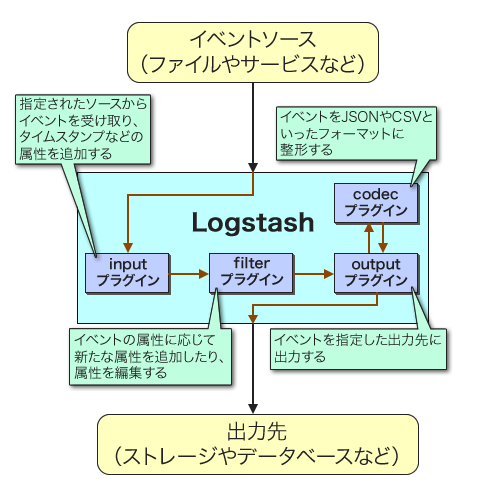
| 種別 | 説明 | 主なプラグイン名 |
|---|---|---|
| input | ログを記録するイベントを監視する | eventlog、file、pipe、stdin、tcpなど |
| codec | inputから受け取ったイベントを指定した形式に整形する | rubydebug、json、fluent、plainなど |
| filter | イベントに対しフィルタ処理を行う | checksum、json、xmlなど |
| output | ログの出力を行う | csv、exec、email、file、elasticsearchなど |
たとえば、inputに﹁stdin﹂、outputに﹁file﹂というプラグインを使用すれば、標準入力からイベントを受け取り、それをファイルに出力することが可能となる。そしてLogstashが注目されている理由の1つのが、出力先として﹁Elasticsearch﹂が利用できる点だ。
図2 ElasticsearchのWebサイト
ElasticsearchはJavaで実装されており、またデータ検索エンジンとして﹁Lucene﹂が組み込まれているのが特徴だ。リアルタイムでのデータ分析や検索機能に優れており、GitHubのコードリポジトリ検索機能や、英ニュースサイト﹁The Guardian﹂のアクセス解析などでElasticSearchが採用されているという。
このElasticsearchをLogstashと組み合わせてログの出力先として使用することで、Elasticsearchが備える強力な検索・分析機能を使ったログの解析が可能となる。また、ElasticsearchはHTTP︵REST︶ベースでクエリを実行できるため、さまざまなクライアントからデータに容易にアクセスできるという特徴もある。
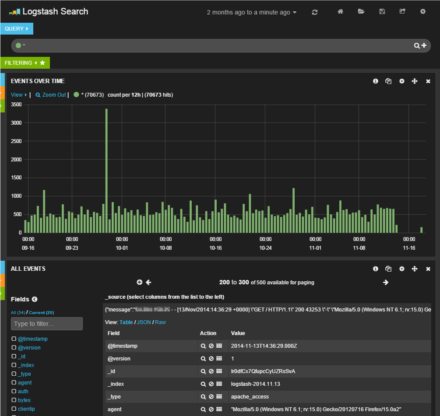
図3 Kibanaのダッシュボード画面
KibanaはWebブラウザ上で操作できるデータ可視化ツールで、Elasticsearchの検索機能を活用し、時系列・属性別にデータを切り出して表やグラフ形式で表示する、といったことが可能だ。
Kibanaは使いやすいユーザーインターフェイスを備えているだけでなく、柔軟なクエリ機能によって素早く必要な情報にアクセスできたり、集計結果データを見やすく表示できる点が評価されており、Kibanaを使うためにElasticsearchやLogstashが使われることも少なくない。
なお、LogstashおよびElasticsearch、Kibanaはすべてオープンソースで開発されており、Elasticsearch社という企業がその開発を主導している。同社はElasticsearchとLogstash、Kibanaの組み合わせを﹁Elasticsearch ELK Stack﹂と呼び、有償でのサポートなども提供している。
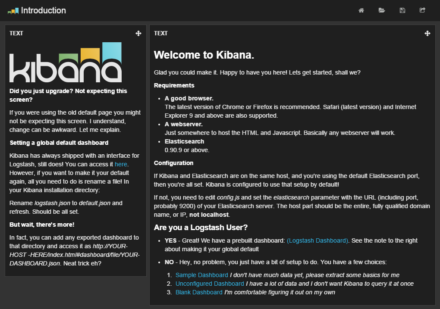
図4 Kibanaの﹁Introduction﹂ページ
ここで、左ペインにある﹁here﹂リンク︵﹁http://<ホスト名>/kibana/index.html#/dashboard/file/logstash.json﹂へのリンク︶をクリックすると、Logstashで取得したログの解析ページが表示される。ただし、この時点ではLogstashでのログ取得を行っていないため、何もデータは表示されない。
図5 Kibanaのログ解析ページ
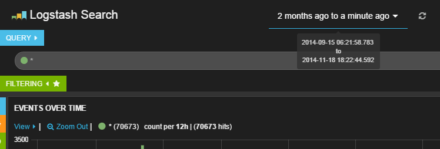
図6対象期間の指定
一番下のイベント一覧画面では、対象となるイベントがリスト表示されており、それぞれをクリックするとイベントの詳細を確認できる︵図7︶。
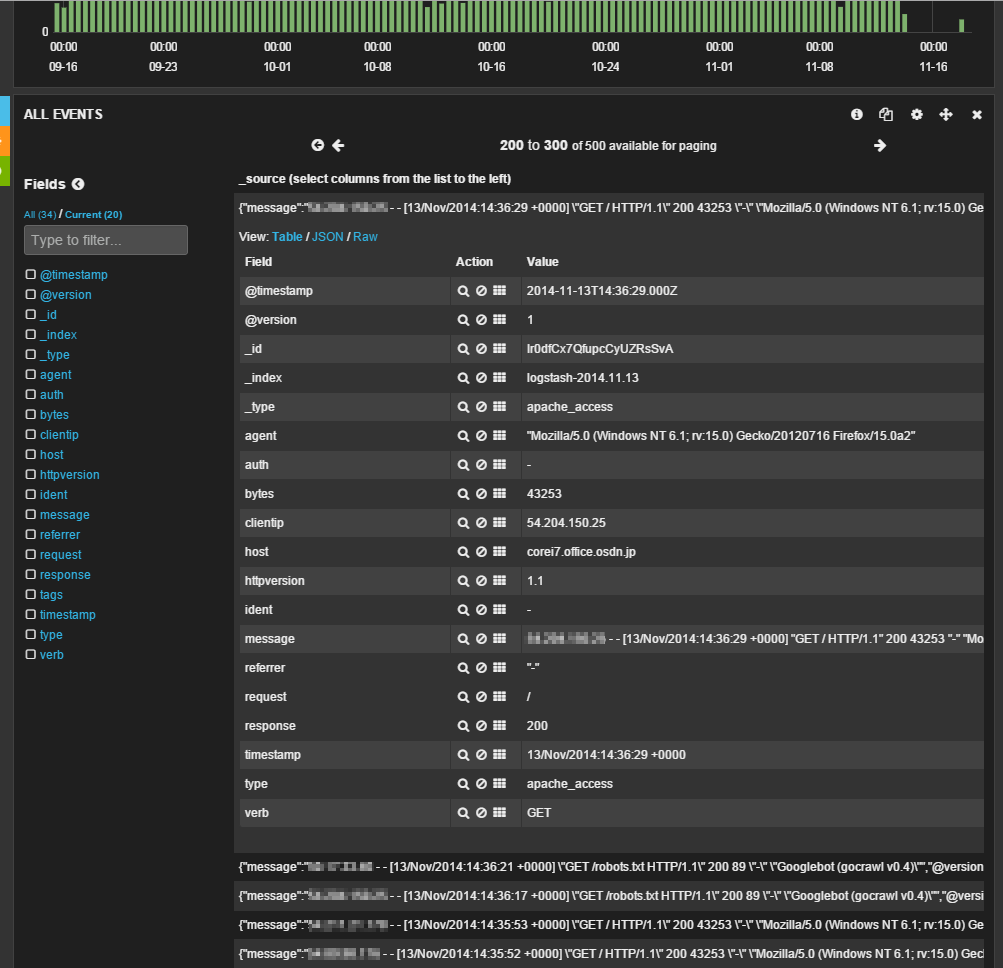
図7イベントの詳細情報
ここでは、左側の﹁Fields﹂で表示させたいフィールドにチェックを入れることで、希望するフィールドの情報のみを表示させることが可能だ︵図8︶。
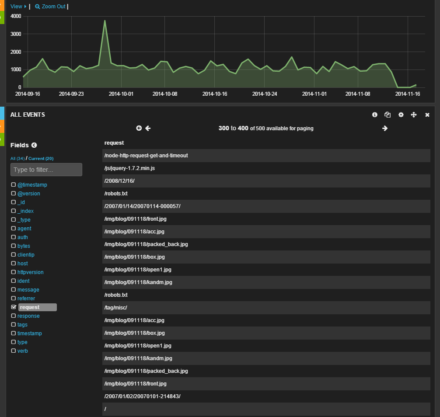
図8﹁request﹂を選択した場合の表示例
グラフ部分では﹁View﹂をクリックすると、表示設定を変更できる。ここでグラフの表示形式や表示単位を指定可能だ︵図9︶。
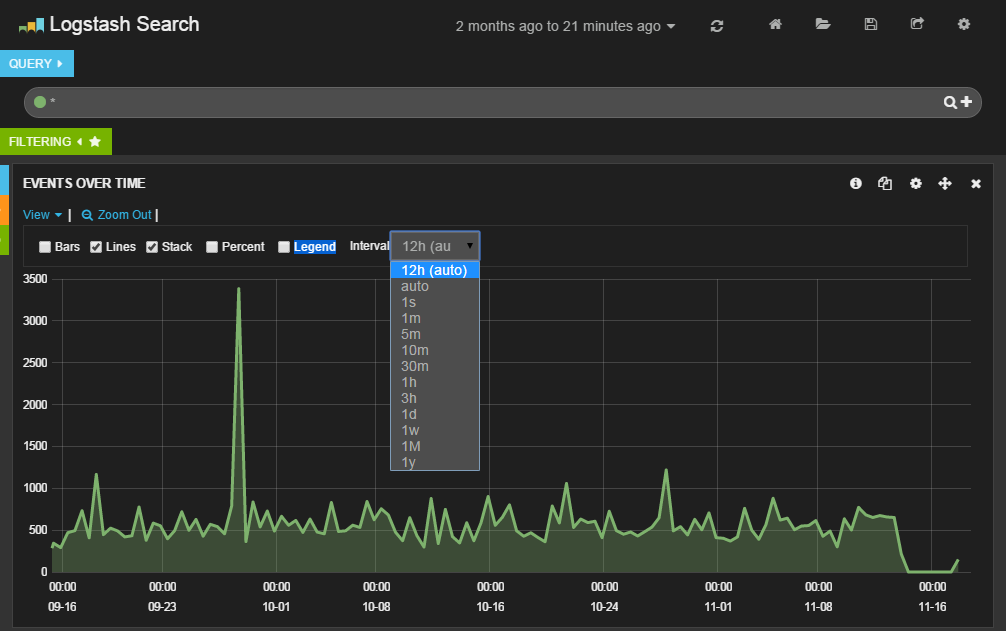
図9グラフの表示設定
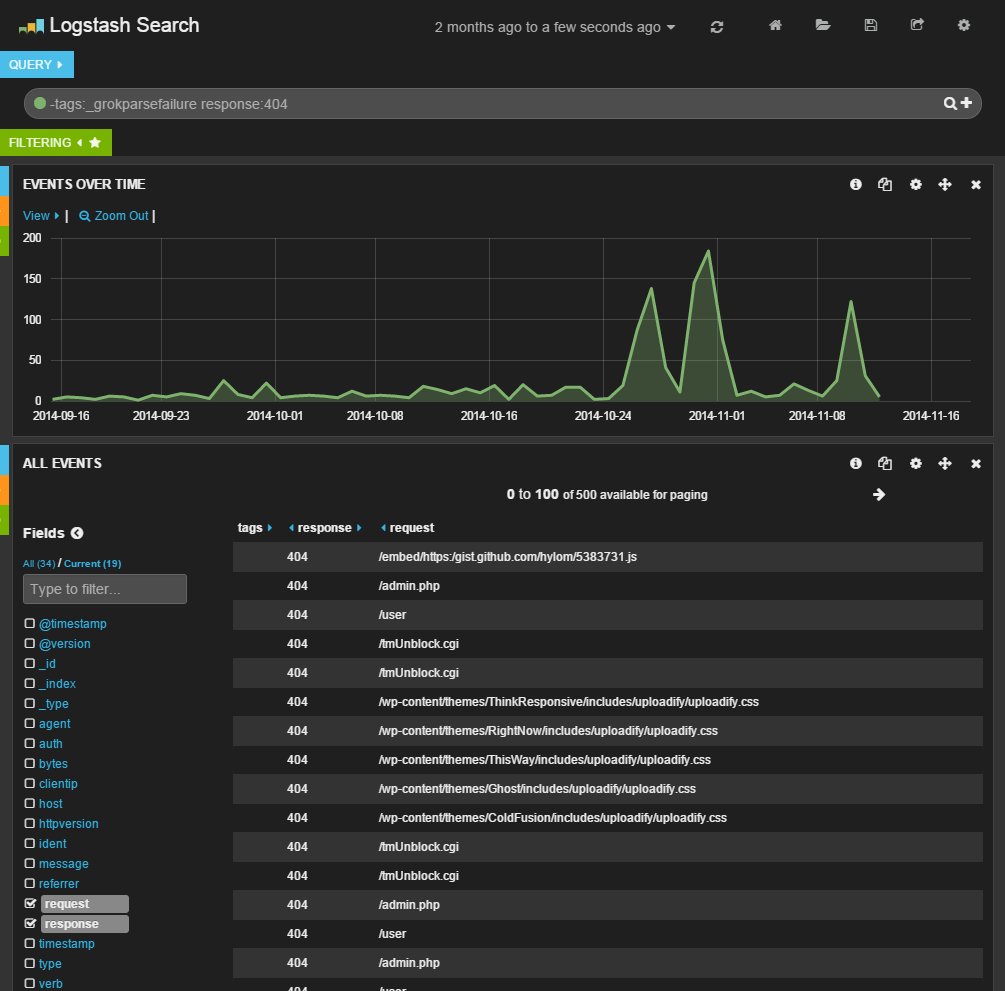
図10ステータスコードが﹁404﹂だったログのみを表示させた例
なお、ここでは一緒に﹁-tags: _grokparsefailure﹂というクエリ文字列も指定している。これは、﹁tags﹂というフィールドに﹁_grokparsefailure﹂という文字列が含まれているログを対象外とするという意味だ。grokではログをパースする場合になんらかの理由でパースに失敗すると、tagsファイルドにこの文字列が設定される。この場合、適切にイベントのフィールドに値が設定されないため、このように指定することで該当するイベントを表示対象外としているのだ。
ちなみに、設定ファイルのfilterセクション内に次の1行を追加することで、grokでのパースに失敗したイベントを破棄することができる。
図10﹁Add Panel﹂アイコン
すると、﹁Add Panel﹂画面が表示され、ここで名称や種別などを指定してパネルを追加できる。今回は指定したフィールドに関する情報を表示する﹁terms﹂形式のパネルを追加し、表示形式︵﹁Style﹂︶として円グラフ︵pie﹂︶を、対象とするフィールドとしてクライアントに返したステータスコードが格納された﹁response﹂を指定し、その出現頻度を表示させてみた︵図11︶。
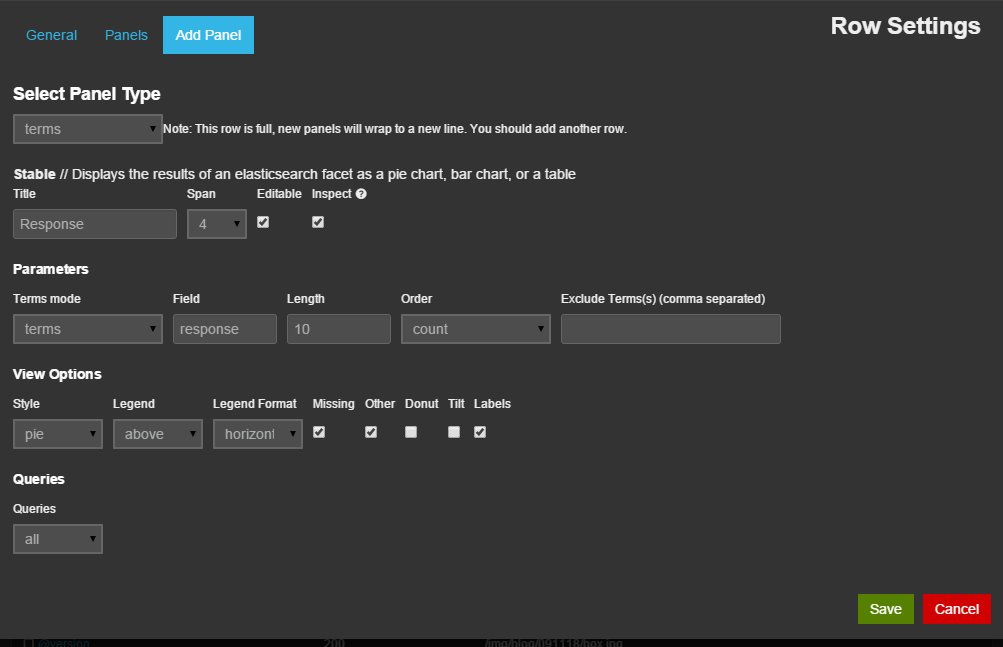
図11﹁Add Panel﹂画面
すると、図12のような円グラフが生成された。ここでは、アクセスの89%に対し﹁200﹂のステータスコードが返されていることが分かる。
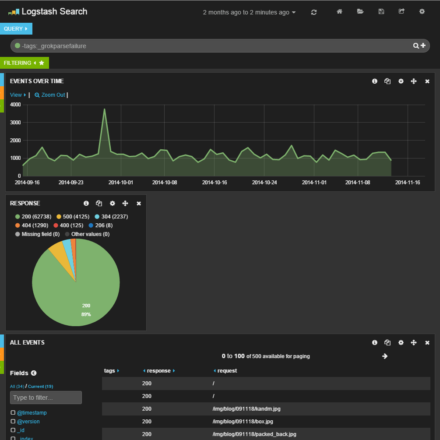
図12新たに追加された﹁response﹂パネル
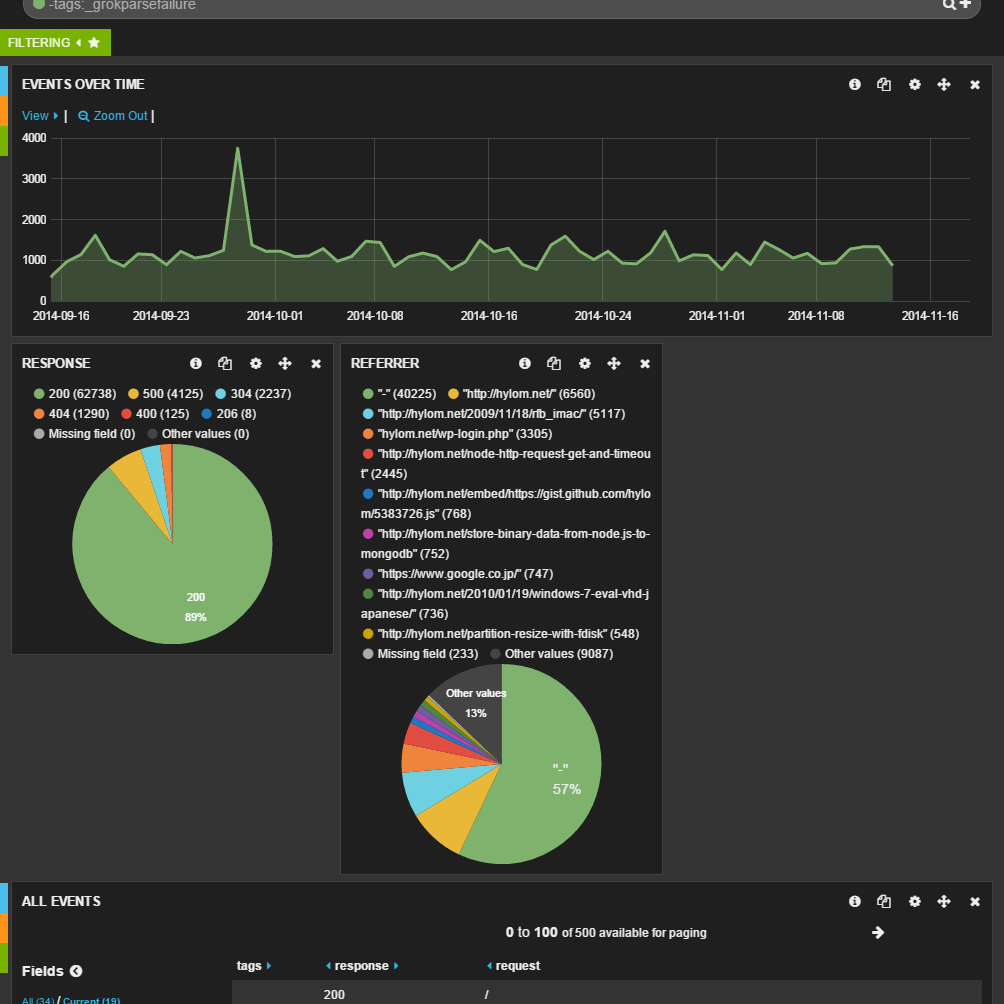
もちろん、複数のパネルを追加することも可能だ。図13はさらにリファラに関する情報を表示するパネルを追加したものだ。
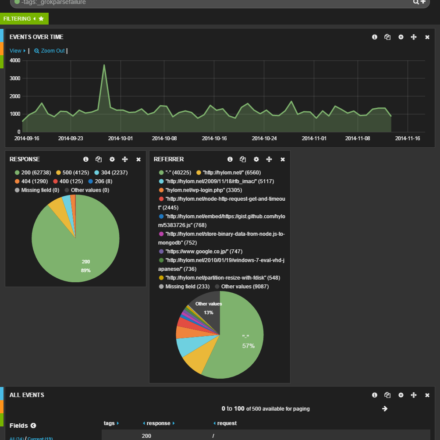
図13パネルは複数追加できる
検索機能に優れた分散型データベース﹁Elasticsearch﹂
Elasticsearchはオープンソースで開発されている分散型データベースシステムだ︵図2︶。﹁Elastic﹂という名前のため勘違いされやすいが、米Amazonが提供しているクラウドサービス﹁Amazon Elastic Compute Cloud︵EC2︶﹂とは無関係だ。Elasticsearchに格納されているログをリアルタイムで可視化できるツール﹁Kibana﹂
ログをElasticsearch内に記録するもう1つのメリットが、Elasticsearch内に格納されているデータを可視化できる﹁Kibana﹂というツールの存在だ︵図3︶。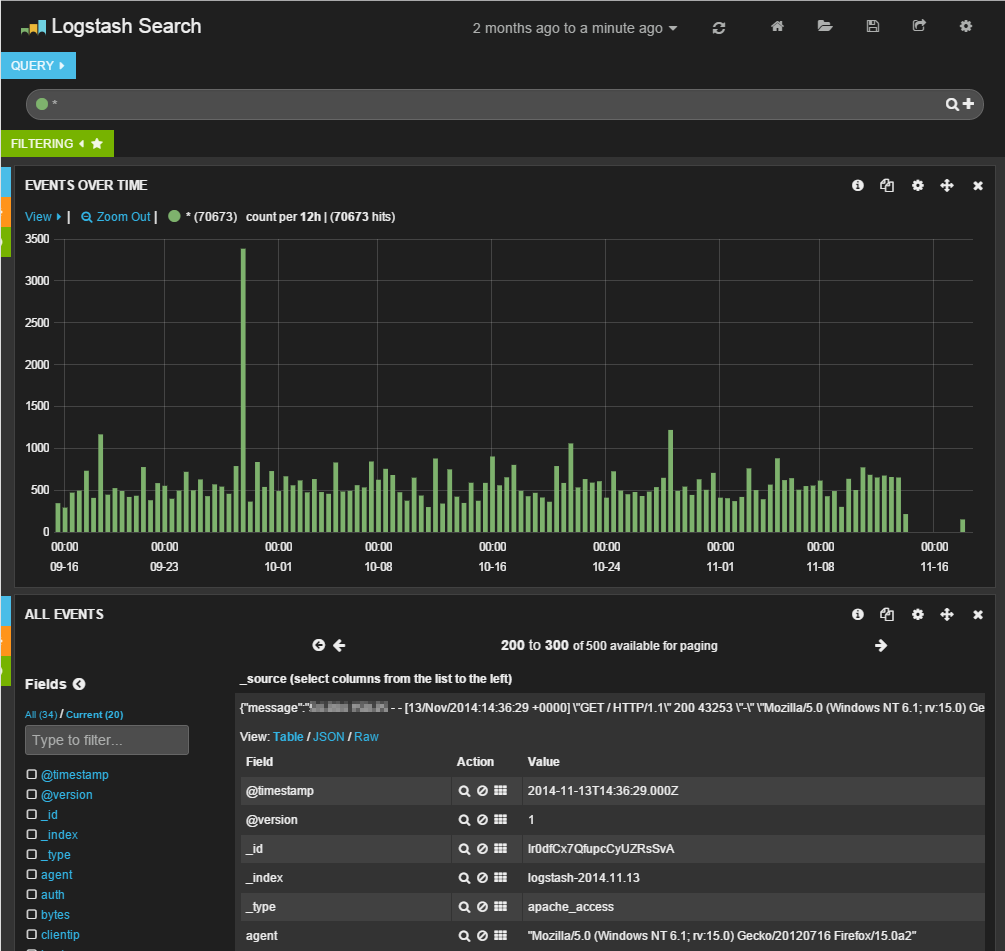
ElasticsearchとLogstash、Kibanaを組み合わせたログ収集/管理環境を構築する
ElasticsearchとLogstashは主にJava︵一部はRuby︶で実装されており、LinuxやMac OS Xを含む各種UNIX、Windowsといったさまざまなプラットフォームで動作する。また、Linux環境向けにはDEB形式およびRPM形式パッケージも配布されており、こちらを利用すれば容易にサービスとしての実行が可能となる。 以下では、Red Hat Enterprise Linux 7互換のCentOS 7︵CentOS 7.0︶にElasticsearchおよびLogstash、Kibanaをインストールし、Apache HTTP Serverのログを解析する環境の構築方法を紹介する。 なお、ElasticsearchやLogstashの利用にはJava Runtime Environment︵JRE︶が必要だ。CentOS 7の場合、これは﹁java-1.7.0-openjdk﹂というパッケージで提供されており、次のようにyumコマンドでインストールできる。ElasticsearchやLogstashを実行するホストに事前にインストールしておこう。# yum install java-1.7.0-openjdkまた、下記ではElasticsearchやLogstash、Kibanaをすべて同一のホストで実行するシンプルな構成例を前提としているが、当然ながらこれらをそれぞれ別ホスト上で実行させることも可能である。その場合、基本的には設定ファイル中でそれぞれのホストを指定する場所を修正すれば良い。また、適宜ファイアウォールの設定なども必要になるので、環境に応じて確認してほしい。
Elasticsearchが提供しているyumリポジトリの追加
ElasticsearchおよびLogstashのソースコードおよびバイナリパッケージはElasticsearchのダウンロードページ︵http://www.elasticsearch.org/download/︶で公開されている。また、yumおよびapt-get用のリポジトリも公開されている︵Elasticsearchドキュメントの﹁repositories﹂ページ︶。今回はこちらのyumリポジトリを利用してインストールを行うことにする。 CentOS環境でElasticsearchのリポジトリを追加するには、リポジトリ情報が格納されている﹁/etc/yum.repos.d/﹂ディレクトリ以下に﹁elasticsearch.repo﹂というファイルを作成し、以下のような内容を記述すれば良い。[elasticsearch-1.4] name=Elasticsearch repository for 1.4.x packages baseurl=http://packages.elasticsearch.org/elasticsearch/1.4/centos gpgcheck=1 gpgkey=http://packages.elasticsearch.org/GPG-KEY-elasticsearch [logstash-1.4] name=logstash repository for 1.4.x packages baseurl=http://packages.elasticsearch.org/logstash/1.4/centos gpgcheck=1 gpgkey=http://packages.elasticsearch.org/GPG-KEY-elasticsearch enabled=1
Elasticsearchのインストールとサービスの起動
Elasticsearchのリポジトリを追加すると、次のようにyumコマンドで﹁elasticsearch﹂パッケージをインストールできるようになる。# yum install elasticsearchこのパッケージをインストールすると、Elasticsearchおよび各種設定ファイルがインストールされるとともに、Elasticsearchを実行するためのelasticsearchユーザーおよびelasticsearchグループが追加される。続いて﹁systemctl daemon-reload﹂コマンドを実行してサービスを登録すれば、﹁systemctl enable﹂および﹁systemctl start﹂コマンドでサービスを開始できる。
# systemctl daemon-reload # systemctl enable elasticsearch.service ln -s '/usr/lib/systemd/system/elasticsearch.service' '/etc/systemd/system/multi-user.target.wants/elasticsearch.service' # systemctl start elasticsearch.serviceここでJREがインストールされていない場合、サービスの開始に失敗する。サービスが開始できなかった場合はJREがインストールされているか確認しよう。また、Elasticsearchのログは﹁/var/log/elasticsearch﹂ディレクトリに格納される。
Elasticsearchの設定
Elasticsearchでは、﹁/etc/elasticsearch﹂ディレクトリ以下に設定ファイルがインストールされる。このディレクトリ内にある﹁elasticsearch.yml﹂がElasticsearchのメインの設定ファイルだ。 ほどんどの設定はデフォルトのままで問題ないが、Kibanaを使用するためにはいくつか設定項目を確認・追加する必要がある。まず1つめは、Elasticsearchが待ち受けを行うIPアドレスとポートの指定だ。IPアドレスについては、﹁network.bind_host﹂という項目で指定できる。デフォルトではこれは次のようにコメントアウトされているので、行頭の﹁#﹂を削除し、IPアドレスを実際に使用するものに書き換えておこう。#network.bind_host: 192.168.0.1使用するポートは﹁transport.tcp.port﹂項目で指定する。デフォルトでは9300番ポートを使用するが、ほかのものに変えたい場合は同様に下記の行を書き換えよう。
#transport.tcp.port: 9300これにら加え、Kibanaから直接Elasticseachを操作できるようにするために設定ファイルの最後に次の行を追加しておく。
# enable cross-origin resource sharing http.cors.enabled: trueこの設定項目について詳しくはドキュメントで解説されているが、この設定項目を追加することでクロスドメインアクセスを許可し、Webブラウザ上で動作するKibanaからElasticseachに対し直接クエリを行えるようになる。 設定が完了したら、systemctlコマンドを実行してelasticseachサービスを再起動して設定を反映させておく。
# systemctl restart elasticsearchまた、KibanaではJavaScriptを使い、Webブラウザから直接Elasticsearchにアクセスを行う。そのため、Kibanaを利用したいホスト︵KibanaにアクセするWebブラウザを実行するPCなど︶から直接Elasticsearchに接続できるよう、ファイアウォールの設定なども行っておこう。 なお、ElasticsearchではHTTPでクエリを投げることで、リモートから簡単にデータの投入や削除を行える仕組みになっている。そのため、ローカルネットワーク内、もしくは信頼できるネットワーク内のみに限定してElasticsearchにアクセスできるよう設定することを強くおすすめする。
Logstashのインストール
続いてはLogstashのインストールだ。先ほどのリポジトリ設定をおこなっていれば、こちらも次のようにyumコマンドで実行できる。# yum install logstashなお、Logstashの一部のプラグインは﹁logstash-contrib﹂という別のパッケージでインストールされている。必要であればこちらもインストールしておこう。 インストールが完了すると、﹁/opt/logstash﹂ディレクトリ以下にlogstash本体および関連ファイルが、﹁/etc/logstash﹂ディレクトリ以下に設定ファイルがインストールされる。また、同時にLogstashをサービスとして実行する際の﹁logstash﹂ユーザーおよびグループが作成される。
Kibanaのインストール
KibanaについてはRPMパッケージは用意されていないため、ダウンロードページから直接ZIPもしくはTAR形式のアーカイブをダウンロードして適当なディレクトリにインストールする形になる。KibanaはHTMLやCSSファイルと、クライアントサイド︵Webブラウザ上︶で実行されるJavaScriptファイルのみで構成されており、サーバーサイドで実行させるコードはない。そのため、適当なWebサーバーでアーカイブに含まれるファイル一式を公開するだけで動作する。 たとえば、CentOS標準のApache HTTP Server︵httpd︶を使用する場合、次のようにすれば﹁http://<ホスト名>/kibana﹂というURLでKibanaにアクセスできるようになる。# cd /var/www/html # wget https://download.elasticsearch.org/kibana/kibana/kibana-3.1.2.tar.gz # tar xvzf kibana-3.1.2.tar.gz # mv kibana-3.1.2 kibana # rm -f kibana-3.1.2.tar.gzなお、この例はKibana 3.1.2を使用しているが、バージョン番号やダウンロードURLは変更される可能性があるので、適宜確認して対応したものを使用してほしい。
Kibanaの設定
Kibanaのアーカイブを展開したディレクトリ内に含まれる﹁config.js﹂ファイルがKibanaの設定ファイルだ。こちらも特に変更すべき部分はないが、KibanaとElasticsearchを別ホストで稼働させている場合はElasticsearchを稼働させているホストを指定する必要がある。これは、、下記の﹁elasticseach﹂行で設定されている。elasticsearch: "http://"+window.location.hostname+":9200",たとえば﹁192.168.1.1﹂というホストでElasticsearchを稼働させている場合、この部分を次のように変更する。
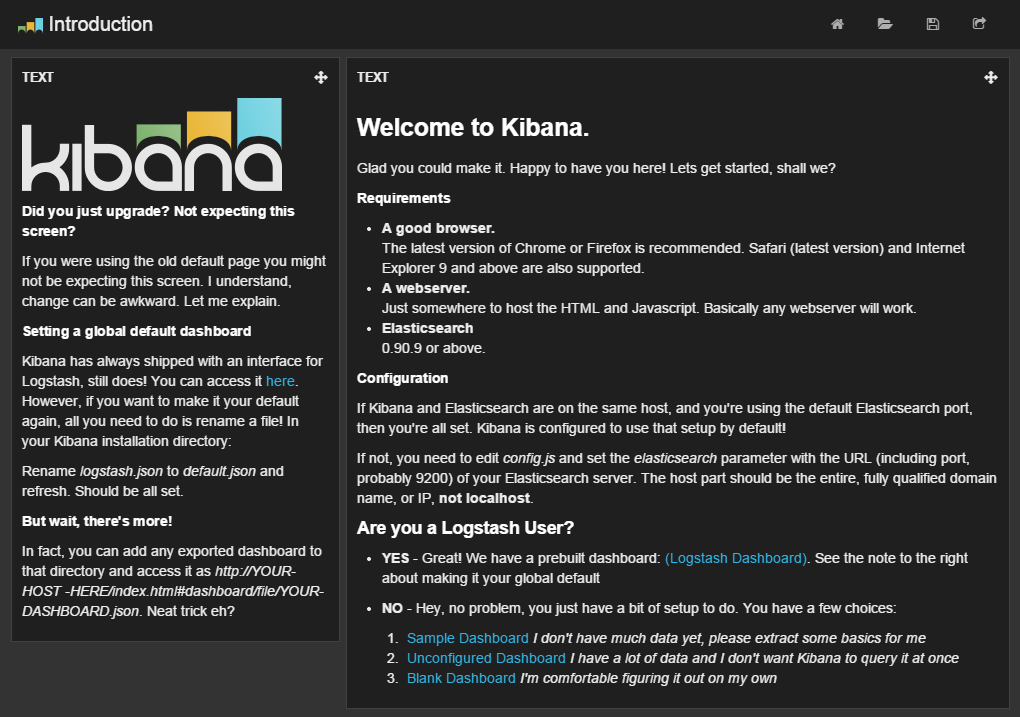
elasticsearch: "http://192.168.1.1:9200",この設定ファイルはJSON形式となっているので、末尾に﹁,﹂が必要な点に注意しよう。 なお、KibanaのJavaScriptコードはすべてWebブラウザ上で実行されるものとなっており、Webブラウザから直接Elasticsearchに対してREST APIを発行してデータを取得してそれらを表示するようになっている。こういった構成上、ElasticsearchサーバーにWebブラウザから直接アクセスできるようになっている必要がある。 設定が完了したら、Kibanaを公開しているURL︵上記の例の場合、﹁http://<ホスト名>/kibana﹂︶にアクセスするとKibanaの﹁Introduction﹂ページが表示されるはずだ︵図4︶。
LogstashでログをElasticsearchに格納する
続いては、Logstashを使ってログをElasticsearchに格納する流れを紹介していこう。 RPMパッケージからLogstashをインストールすると、Logstashをサービスとして実行できるようになる。これは、リアルタイムでイベントをログとして記録したい場合に有用だ。また、﹁/opt/logstash/bin/﹂ディレクトリ以下にインストールされた﹁logstash﹂コマンドをシェルから実行することもできる。既存のログファイルに記録されているログをElasticsearchに投入する際は、こちらを利用する。 以下では、まずApache HTTP Serverの既存のログファイルからElasticsearchへとログを取り込む方法を説明する。続いて、Kibanaの操作方法と、リアルタイムでApache HTTP ServerのログをElasticsearchに記録する方法を紹介しよう。設定ファイルの書式
Logstashでは、使用するinputやoutput、filter、codecなどのプラグインと、それらの設定パラメータを記述した設定ファイルを用意し、それを引数で指定してlogstashコマンドを実行することでログの取り込みを行える。設定ファイルは、以下のような形式で記述する。<プラグインの種類> {
<使用するプラグイン1> {
<設定パラメータ1> => <設定する値>
<設定パラメータ2> => <設定する値>
:
:
}
<使用するプラグイン2> {
<設定パラメータ1> => <設定する値>
<設定パラメータ2> => <設定する値>
:
:
}
:
:
}
なお、﹁#﹂から行末まではコメントとして無視される。
﹁プラグインの種類﹂では、﹁input﹂もしくは﹁filter﹂、﹁output﹂を指定する。また、﹁使用するプラグイン﹂にはプラグイン名を指定する。プラグインは複数指定可能で、ここで指定した順序でイベントは処理される。
多くのプラグインでは設定パラメータが用意されており、それらは﹁<パラメータ名> => <値>﹂という形式で指定する。値にはBoolean︵﹁true﹂もしくは﹁false﹂︶、文字列、配列、ハッシュが指定できる。文字列については通常は﹁"﹂で囲んで指定するが、文字列中に空白などが含まれない場合は囲まなくても文字列として扱われる。配列はRubyやPythonの配列リテラルと同様、以下の形式で記述する。
[<1つめの値>, <2つめの値>, ...]また、ハッシュについてはRubyと同じ形式で記述する。
{
『<キー1>』=> <値1>
『<キー2>』=> <値2>
:
:
}
そのほか、設定ファイル中ではif〜else文による条件分岐も可能だ。詳しくはLogstashのドキュメントを参照して欲しい。
既存のログファイルからログを取り込む
既存のApacheログファイルからログを取り込む場合の設定ファイルは、以下のようになる。今回は﹁apache_import.conf﹂というファイルにこの内容を記述した。input {
stdin { }
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
locale => "en"
}
mutate {
replace => { "type" => "apache_access" }
}
}
output {
# stdout { codec => rubydebug }
elasticsearch { host => '172.17.4.199' }
}
まず、inputプラグインとしては﹁stdin﹂プラグインを使用している。このプラグインは、標準入力からテキストを読み込んで、その各行を1つのイベントとして処理するものだ。
Logstashではイベントをハッシュ形式のデータとして取り扱い、そのキーを﹁フィールド﹂と呼ぶ。stdinプラグインでは、入力されたデータを次のようなイベントに変換し、filterプラグインに渡す。
{
"message" => "<入力されたテキスト>",
"@version" => "1",
"@timestamp" => "<読み込み実行時のタイムスタンプ",
"host" => "<コマンドを実行したホスト名>"
}
filterセクションではテキストをパースする﹁grok﹂と、タイムスタンプ文字列を参照してそれをイベントのタイムスタンプとして設定する﹁date﹂、イベントに任意のフィールドを追加する﹁mutate﹂プラグインを指定している。
grokプラグインは、イベント内の指定したフィールドをパースし、そこから適切なフィールドと値を生成する処理を行うものだ。
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
﹁match﹂パラメータで対象とするフィールドと、書式文字列を指定する。ここでは﹁message﹂フィールドを対象とし、書式文字列としてApache HTTP ServerのCombined形式ログをパースするための﹁"%{COMBINEDAPACHELOG}"﹂を指定している。
今回の場合、たとえば﹁***.***.**.*** - - [10/Nov/2014:14:30:27 +0000] "GET /2007/03/ HTTP/1.1" 200 - "-" "Mozilla/5.0 (compatible; AhrefsBot/5.0; +http://ahrefs.com/robot/)"﹂というログを入力すると、次のようなイベントが生成される。
{
"message" => "***.***.**.*** - - [10/Nov/2014:14:30:27 +0000] \"GET /2007/03/ HTTP/1.1\" 200 - \"-\" \"Mozilla/5.0 (compatible; AhrefsBot/5.0; +http://ahrefs.com/robot/)\"",
"@version" => "1",
"@timestamp" => "2014-11-19T15:37:46.934Z",
"host" => "corei7.office.osdn.jp",
"clientip" => "***.***.**.***",
"ident" => "-",
"auth" => "-",
"timestamp" => "10/Nov/2014:14:30:27 +0000",
"verb" => "GET",
"request" => "/2007/03/",
"httpversion" => "1.1",
"response" => "200",
"referrer" => "\"-\"",
"agent" => "\"Mozilla/5.0 (compatible; AhrefsBot/5.0; +http://ahrefs.com/robot/)\""
}
なお、Combined形式以外のフォーマットのログを対象としたい場合、この別途それに応じた書式文字列を指定する必要がある。
次のdateプラグインは、指定したフィールド内の文字列からタイムスタンプを取り出し、それをイベントのタイムスタンプ︵﹁@timestamp﹂フィールドの値︶に設定するものだ。
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
locale => "en"
}
この場合、﹁timestamp﹂フィールドから文字列を取り出してパースしてタイムスタンプとして使用する。たとえば、grokプラグインが出力した上記のイベントの場合、﹁2014年11月10日14時30分27秒︵GMT︶﹂がイベントのタイムスタンプとして設定される。
mutateプラグインは、イベントに対してフィールドを追加したり、文字列を置き換えたりといった加工を行うものだ。
mutate {
replace => { "type" => "apache_access" }
}
ここでは、﹁type﹂というフィールドに﹁apache_access﹂という文字列を指定するよう設定している。
最後に、outputセクションで出力先として﹁elasticsearch﹂プラグインを指定している。
output {
# stdout { codec => rubydebug }
elasticsearch { host => '172.17.4.199' }
}
elasticsearchプラグインでは、﹁host﹂パラメータで対象とするElasticsearchが稼働しているホストを指定する。今回は、﹁172.17.4.199﹂というホストを使用している。
なお、コメントアウトしている﹁# stdout { codec => rubydebug }﹂の行は、イベントを標準出力に﹁rubydebug﹂形式で出力するという設定だ。行頭の﹁#﹂を削除して有効にすれば、Elasticsearchにイベントを送信する前に標準出力にその内容が表示されるようになる。正しくログがパースされているか確認したい場合などに有用だが、大量のログを処理する場合は出力も大量になるので注意したい。
設定ファイルの作成後、次のようにlogstashコマンドを実行することで、ログの内容をElasticsearchに取り込める。
$ /opt/logstash/bin/logstash -f apache-import.conf < <アクセスログファイル>
Kibanaでログを解析する
Elasticsearch内にログを取り込んだら、Kibanaでそのログを確認してみよう。WebブラウザでKibanaを公開しているURL︵﹁http://<ホスト名>/kibana﹂︶にアクセスし、左ペインにある﹁here﹂リンク︵﹁http://<ホスト名>/kibana/index.html#/dashboard/file/logstash.json﹂へのリンク︶をクリックすると、ログ解析結果が表示されるはずだ︵図5︶。Kibanaの基本的な操作
KibanaのLogstash向けデフォルト設定では、一番上にクエリ文字列を入力するテキストエリア、その下に時間ごとのイベント数を示すグラフ、そして一番下にイベント一覧が表示される。また、最上段︵﹁Logstash Search﹂の右側︶には解析対象とする期間を指定するドロップダウンリストが用意されており、ここで対象期間を指定できる︵図6︶。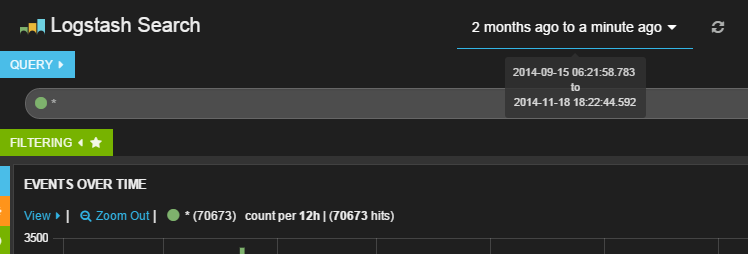
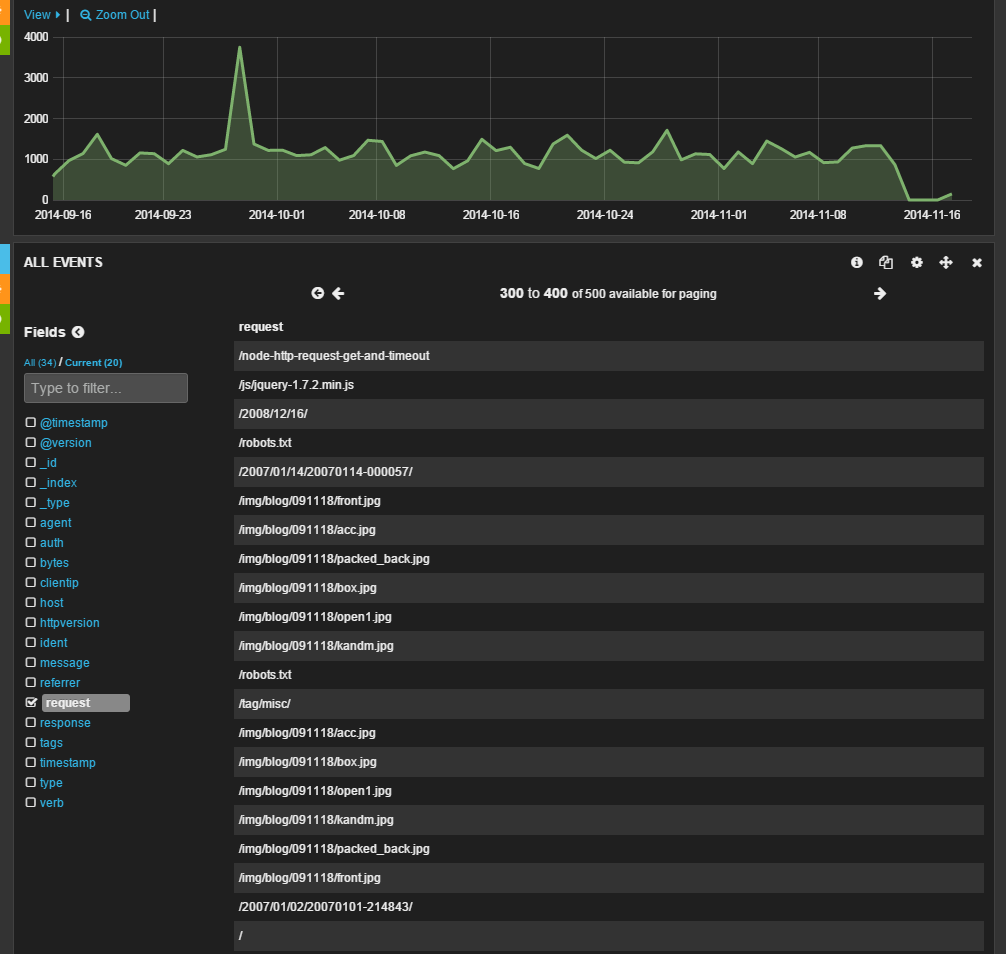
クエリの実行
一番上に表示されているテキストボックスに検索クエリを入力することで、特定の条件に合致するログのみを表示させることが可能となる。クエリは、﹁<フィールド名>:<値>﹂という形式で指定できる。 たとえば、﹁response:404﹂というクエリを指定すると、クライアントに対して返したステータスコードが﹁404﹂となっているログのみを表示できる︵図10︶。if "_grokparsefailure" in [tags] { drop { } }
パネルのカスタマイズ
デフォルトで表示されているグラフだけでなく、新たな表示項目︵パネル︶を追加することも可能だ。グラフの左側に隠れている青・橙・緑のバーにマウスポインタを合わせると表示される緑色の﹁+﹂アイコンをクリックする︵図10︶。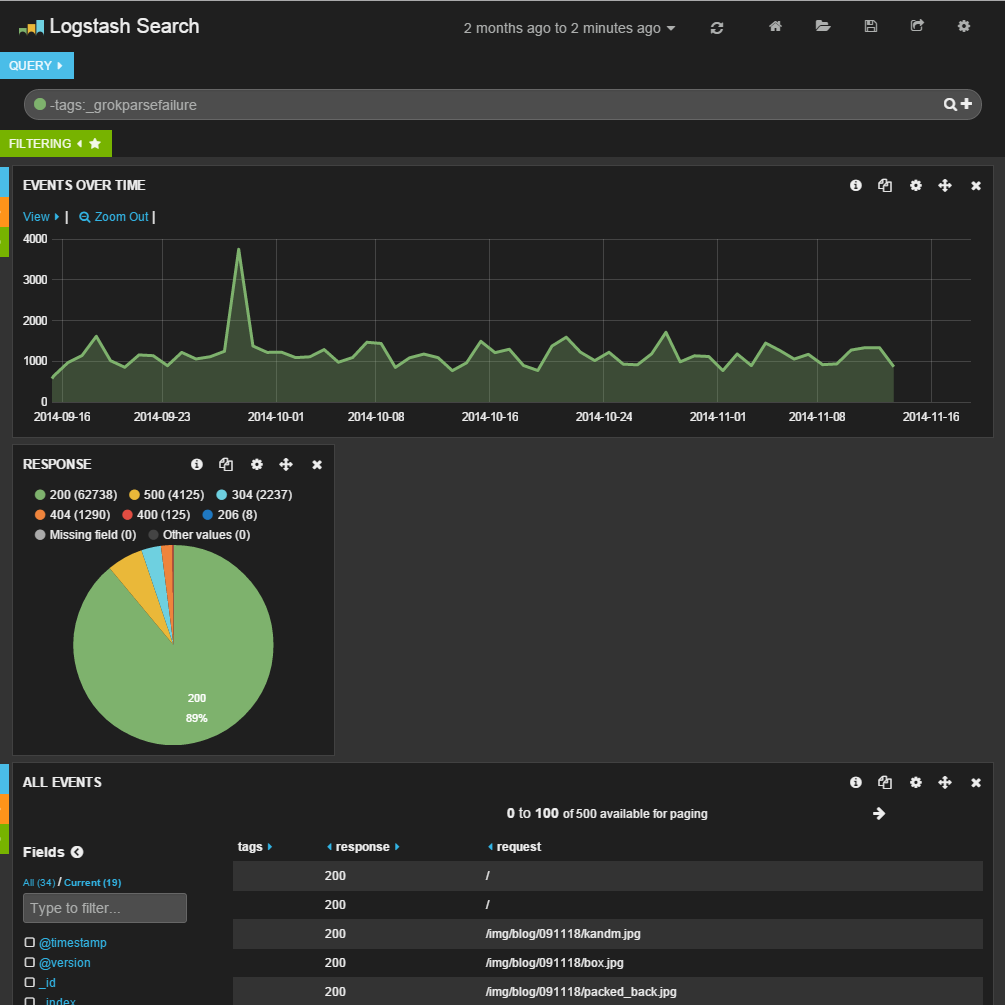
ログをリアルタイムでElasticsearchに格納する
さて、ここまでではファイル内に記録されているログをまとめてElasticsearch内に格納していたが、リアルタイムでログをElasticsearchに送信する方法についても紹介しよう。 この場合、inputとして指定したファイルを監視し、そこに新たに記録された行をリアルタイムでElasticsearchに送信できる﹁file﹂プラグインを利用すれば良い。 また、リアルタイムでログを送信したい場合、logstashサービスを使用するのが一般的だ。logstashサービスでは、設定ファイルとして﹁/etc/logstash/conf.d﹂ディレクトリ内にあるファイルが使用される。複数の設定ファイルを同時に使用することも可能だ。今回は、次のような内容が記述された﹁/etc/logstash/conf.d/apache-access_log.conf﹂という設定ファイルを作成して使用した。input {
file {
path => "/var/log/httpd/access_log"
start_position => beginning
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
locale => "en"
}
mutate {
replace => { "type" => "apache_access" }
}
}
output {
elasticsearch { host => '172.17.4.199' }
}
ここでの設定内容は先ほどファイルからのログ取り込みで使用したものとほぼ同じだが、inputにfileプラグインを指定し、読み込み先を指定する﹁path﹂パラメータにApace HTTP Serverのアクセスログファイル︵﹁/var/log/httpd/access_log﹂︶を、最初の読み込み開始個所を指定する﹁start_position﹂パラメータにはファイルの最初を示す﹁begining﹂を指定している。
設定ファイルを用意したら、次のようにしてlogstashサービスを起動する。
# systemctl enable logstash # systemctl start logstashlogstashサービスのログは﹁/var/log/logstash/﹂ディレクトリ以下に格納されているので、もし問題が発生した場合、ここに格納されているログを確認すると良いだろう。