1. はじめに

2. 環境
anacondaで,以下のような仮想環境comicを作成します.
conda create -n comic python=3.5
source activate comic
conda install pandas matplotlib jupyter notebook scipy scikit-learn seaborn scrapy
pip install tensorflow
ymlファイルはこちらです.後編で必要になるので,tensorflowやscikit-learnを入れてあります.また,可視化にpairplot()を使うので,seabornを入れます.
3. データの取得
3.1 ソース
文化庁メディア芸術データベースに,約46年間分︵1969年11月3日号-2016年7月25日号︶のジャンプの目次が公開されています5.

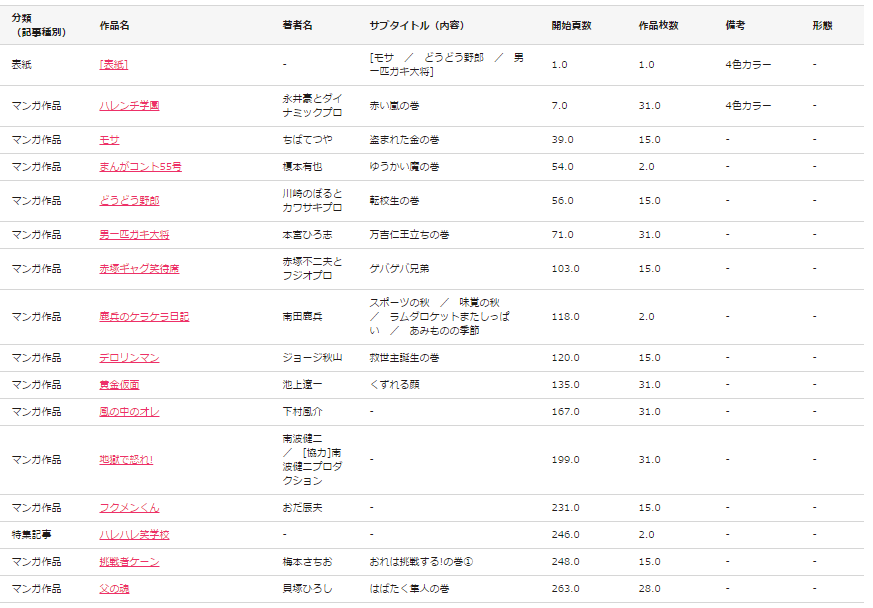 上図は,ジャンプ1969年11月3日号の目次を調査した例です.以下では,コメント欄でご紹介頂いた,Web APIを用いて目次情報を抽出します.
上図は,ジャンプ1969年11月3日号の目次を調査した例です.以下では,コメント欄でご紹介頂いた,Web APIを用いて目次情報を抽出します.
3.2 Web API
文化庁のサーバへの負担を極力抑えるため,可能な限り私のgithubから加工済みデータを取得頂ますようお願い致します.notebookはこちらですので,使っていただけると幸いです. 文化庁メディア芸術データベース マンガ分野 WebAPIを用いて,分析に必要なデータを入手します.なお,python3を使ったweb APIの利用については,Python3でjsonを返却するwebAPIにアクセスして結果を出力するまでを参考にさせて頂きました.import
import json
import urllib.request
from time import sleep
雑誌巻号検索結果の取得
以下の関数search_magazine()を使って,週刊少年ジャンプの雑誌巻号情報を検索します.この関数で取得したユニークIDは,次節の「雑誌巻号情報の取得」に必要になります.
def search_magazine(key='JUMPrgl', n_pages=25):
"""
「ユニークID」「雑誌巻号ID」あるいは「雑誌コード」にkey含む雑誌を,
n_pages分取得する関数です.
"""
url = 'https://mediaarts-db.bunka.go.jp/mg/api/v1/results_magazines?id=' + \
key + '&page='
magazines = []
for i in range(1, n_pages):
response = urllib.request.urlopen(url + str(i))
content = json.loads(response.read().decode('utf8'))
magazines.extend(content['results'])
return magazines
idで﹁ユニークID﹂﹁雑誌巻号ID﹂﹁雑誌コード﹂を,pageで検索ページ番号︵1ページあたり100件,デフォルトは1︶を指定することができます.週刊少年ジャンプは﹁雑誌巻号ID﹂にJUMPrglを含むため,id=JUMPrglを指定します.また,週刊少年ジャンプの検索結果は合計24ページ︵2320件︶あるため,pageに1から24を順次指定する必要があります.詳細はWebAPI仕様をご参照ください.
なお,2017年3月31日より文化庁メディア芸術データベースのURLが変更されたため,WebAPI仕様に記載のリクエストURL︵https://mediaarts-db.jp/mg/api/v1/results_magazines︶ではなく,新しいURL︵https://mediaarts-db.bunka.go.jp/mg/api/v1/results_magazines︶を使用する必要があることにご注意ください.
雑誌巻号情報の取得
以下の関数extract_data()で必要な目次情報を抽出し,save_data()で目次情報を保存します.
def extract_data(content):
"""
contentに含まれる目次情報を取得する関数です.
- year: 発行年
- no: 号数
- title: 作品名
- author: 著者
- color: カラーか否か
- pages: 掲載ページ数
- start_page: 作品のスタートページ
- best: 巻頭から数えた掲載順
- worst: 巻末から数えた掲載順
"""
# マンガ作品のみ抽出します.
comics = [comic for comic in content['contents']
if comic['category']=='マンガ作品']
data = []
year = int(content['basics']['date_indication'][:4])
# 号数が記載されていない場合があるので,例外処理が必要です.
try:
no = int(content['basics']['number_indication'])
except ValueError:
no = content['basics']['number_indication']
for comic in comics:
title= comic['work']
if not title:
continue
# ページ数が記載されていない作品があるので,例外処理が必要です.
# 特に理由はないですが,無記載の作品は10ページとして処理を進めます.
try:
pages = int(comic['work_pages'])
except ValueError:
pages = 10
# 「いぬまるだしっ」等,1週に複数話掲載されている作品に対応するため
# data中にすでにtitleが含まれる場合は,新規datumとして登録せずに,
# 既存のdatumのページ数のみ加算します.
if len(data) > 0 and title in [datum['title'] for datum in data]:
data[[datum['title'] for datum in
data].index(title)]['pages'] += pages
else:
data.append({
'year': year,
'no': no,
'title': comic['work'],
'author': comic['author'],
'subtitle': comic['subtitle'],
'color': int('カラー' in comic['note']),
'pages': int(comic['work_pages']),
'start_pages': int(comic['start_page'])
})
# 企画物のミニマンガを除外するため,合計5ページ以下のdatumはリストから除外します.
filterd_data = [datum for datum in data if datum['pages'] > 5]
for n, datum in enumerate(filterd_data):
datum['best'] = n + 1
datum['worst'] = len(filterd_data) - n
return filterd_data
comicのtitleがdata中にある場合は,別datumとしてdataに追加せず,既存のdatumのpagesを加算する処理を行っています.また,例えば﹁ピューと吹く!ジャガー﹂は,その人気に関係なく︵実際めちゃくちゃ面白かったです︶,連載中は常に雑誌の最後に掲載されていました.これを外れ値として除外するかどうかで悩みましたが,結局残すことにしました.
def save_data(magazines, offset=0, file_name='data/wj-api.json'):
"""
magazinesに含まれる全てのmagazineについて,先頭からoffset以降の巻号の
目次情報を取得し,file_nameに保存する関数です.
"""
url = 'https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine?id='
# ファイル先頭行
if offset == 0:
with open(file_name, 'w') as f:
f.write('[\n')
with open(file_name, 'a') as f:
# magazines中のmagazine毎にWeb APIを叩きます.
for m, magazine in enumerate(magazines[offset:]):
response = urllib.request.urlopen(url + str(magazine['id']),
timeout=30)
content = json.loads(response.read().decode('utf8'))
# 前記の関数extract_data()で,必要な情報を抽出します.
comics = extract_data(content)
print('{0:4d}/{1}: Extracted data from {2}'.\
format(m + offset, len(magazines), url + str(magazine['id'])))
# comics中の各comicについて,file_nameに情報を保存します.
for n, comic in enumerate(comics):
# ファイル先頭以外の,magazineの最初のcomicの場合は,
# まず',\n'を追記.
if m + offset > 0 and n == 0:
f.write(',\n')
json.dump(comic, f, ensure_ascii=False)
# 最後のcomic以外は',\n'を追記.
if not n == len(comics) - 1:
f.write(',\n')
print('{0:9}: Saved data to {1}'.format(' ', file_name))
# サーバへの負荷を抑えるため,必ず一時停止します.
sleep(3)
# ファイル最終行
with open(file_name, 'a') as f:
f.write(']')
sleep()で一時停止していることにご注意ください.
なお,ここでも,WebAPI仕様に記載のリクエストURL︵https://mediaarts-db.jp/mg/api/v1/magazine︶ではなく,新しいURL︵https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine︶を使用する必要があることにご注意ください.
実行
以上の関数を利用して,Web APIから目次情報を取得し,data/wj-api.jsonに保存します.
magazines = search_magazine()
save_data(magazines)
# 0/2320: Extracted data from https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine?id=323270
# : Saved data to data/wj-api.json
# 1/2320: Extracted data from https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine?id=323269
# : Saved data to data/wj-api.json
# ...
# 447/2320: Extracted data from https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine?id=322833
# : Saved data to data/wj-api.json
#---------------------------------------------------------------------------
#gaierror Traceback (most recent call last)
#/home/anaconda3/envs/comic/lib/python3.5/urllib/request.py in do_open(self, http_class, req, **http_conn_args)
# 1253 try:
#-> 1254 h.request(req.get_method(), req.selector, req.data, headers)
# 1255 except OSError as err: # timeout error
タイムアウトした場合は,offsetを利用して再開します.例えば,447/2320でタイムアウトした場合は,save_data(offset=448)を実行します.
save_data(magazines, offset=448)
# 448/2320: Extracted data from https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine?id=322832
# : Saved data to data/wj-api.json
# 449/2320: Extracted data from https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine?id=322831
# : Saved data to data/wj-api.json
#...
3.3 (参考)スクレイピング
comicを作成します.
scrapy startproject comic
すると,以下のようなディレクトリが作成されるはずです(公式チュートリアル).
comic/
scrapy.cfg # deploy configuration file
comic/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
以下のcomic_spider.pyをcomic/spidersに置きます.
# -*- coding: utf-8 -*-
import scrapy
class WjSpider(scrapy.Spider):
"""
start_urlsを起点に再帰的に以下の目次情報を抽出するspiderです.
ここでstart_urlsは,文化庁メディア芸術データベースに登録されている
週刊少年ジャンプの目次情報のうち,最も古いもの(1969年11月3日号)です.
- year: 発行年
- no: 号数
- title: 作品名
- author: 著者
- color: カラーか否か
- pages: 掲載ページ数
- start_page: 作品のスタートページ
- best: 巻頭から数えた掲載順
- worst: 巻末から数えた掲載順
"""
name = 'wj'
start_urls = [
'http://mediaarts-db.bunka.go.jp/mg/magazines/323270'
]
n_page = 0
def parse(self, response):
""" spider本体です. """
year = int(response.css('section.block tr td::text').extract()[3][:4])
try:
no = int(response.css('section.block tr td::text').extract()[8])
except ValueError:
no = response.css('section.block tr td::text').extract()[8]
# マンガ作品のみ抽出します.
comics = [comic for comic in response.css('table.infoTbl2 tr')
if len(comic.css('td::text')) > 0
and comic.css('td::text')[0].extract() == 'マンガ作品']
data = []
for comic in comics:
title = comic.css('a::text').extract_first()
if not title:
continue
# ページ数が記載されていない作品があるので,例外処理が必要です.
# 特に理由はないですが,無記載の作品は10ページとして処理を進めます.
try:
pages = float(comic.css('td::text')[6].extract())
except ValueError:
pages = 10
# 「いぬまるだしっ」等,1週に複数話掲載されている作品に対応するため
# data中にすでにtitleが含まれる場合は,新規datumとして登録せずに,
# 既存のdatumのページ数のみ加算します.
if len(data) > 0 and title in [datum['title'] for datum in data]:
data[[datum['title'] for datum in
data].index(title)]['pages'] += pages
else:
data.append({
'year': year,
'no': no,
'title': comic.css('a::text').extract_first(),
'author': comic.css('td::text')[3].extract(),
'subtitle': comic.css('td::text')[4].extract(),
'color': comic.css('td::text')[7].extract().count('カラー'),
'pages': pages,
'start_page': float(comic.css('td::text')[5].extract())})
# 企画物のミニマンガを除外するため,合計5ページ以下のdatumはリストから除外します.
filtered_data = [datum for datum in data if datum['pages'] > 5]
for n, datum in enumerate(filtered_data):
datum['best'] = n + 1
datum['worst'] = len(filtered_data) - n
yield datum
# 次号の情報を再帰的に取得します.
next_page = response.css('li.nxt a::attr(href)').extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
サーバに負荷をかけないよう,必ずsettings.pyのDOWNLOAD_DELAYを設定する必要があります(デフォルトでコメントアウトされていました).また,日本語でデータを吐き出したいので,FEED_EXPORT_ENCODINGをutf-8に設定します.
### ----- 略 -----
DOWNLOAD_DELAY = 3
FEED_EXPORT_ENCODING = 'utf-8'
### ----- 略 -----
以下を実行して,データを取得します.
scrapy crawl wj -o wj.json
4. データの分析
wj-api.jsonだけででかなり遊べます6.notebookはこちらですので,使っていただけると幸いです.なお,以下では,dataディレクトリ配下にwj-api.jsonがあることを前提に話を進めます.
4.1 準備
日本語で各作品のタイトルを表示したいので,matplotlibで日本語を描画 on Ubuntuを参考に設定します.Ubuntu以外をお使いの方は,適宜ご対応ください.import json
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
sns.set(style='ticks')
import matplotlib
from matplotlib.font_manager import FontProperties
font_path = '/usr/share/fonts/truetype/takao-gothic/TakaoPGothic.ttf'
font_prop = FontProperties(fname=font_path)
matplotlib.rcParams['font.family'] = font_prop.get_name()
4.2 ComicAnalyzer
wj-api.json分析用に,次のようなクラスComicAnalyzerを定義します.
class ComicAnalyzer():
"""漫画雑誌の目次情報を読みだして,管理するクラスです."""
def __init__(self, data_path='data/wj-api.json', min_week=7, short_week=10):
"""
初期化時に,data_pathにある.jsonファイルから目次情報を抽出します.
- self.data: 全目次情報を保持するリスト型
- self.all_titles: 全作品名情報を保持するリスト型
- self.serialized_titles: min_week以上連載した全作品名を保持するリスト型
- self.last_year: 最新の目次情報の年を保持する数値型
- self.last_no: 最新の目次情報の号数を保持する数値型
- self.end_titles: self.serialized_titlesのうち,self.last_yearおよび
self.last_noまでに終了した全作品名を保持するリスト型
- self.short_end_titles: self.end_titlesのうち,short_week週以内に
連載が終了した作品名を保持するリスト型
- self.long_end_titles: self.end_titlesのうち,short_week+1週以上に
連載が継続した作品名を保持するリスト型
"""
self.data = self.read_data(data_path)
self.all_titles = self.collect_all_titles()
self.serialized_titles = self.drop_short_titles(self.all_titles, min_week)
self.last_year = self.find_last_year(self.serialized_titles[-100:])
self.last_no = self.find_last_no(self.serialized_titles[-100:], self.last_year)
self.end_titles = self.drop_continued_titles(
self.serialized_titles, self.last_year, self.last_no)
self.short_end_titles = self.drop_long_titles(
self.end_titles, short_week)
self.long_end_titles = self.drop_short_titles(
self.end_titles, short_week + 1)
def read_data(self, data_path):
""" data_pathにあるjsonファイルを読み出して,全ての目次情報をまとめたリストを返します. """
with open(data_path, 'r', encoding='utf-8') as f:
data = json.load(f)
return data
def collect_all_titles(self):
""" self.dataから全ての作品名を抽出したリストを返します. """
titles = []
for comic in self.data:
if comic['title'] not in titles:
titles.append(comic['title'])
return titles
def extract_item(self, title='ONE PIECE', item='worst'):
""" self.dataからtitleのitemをすべて抽出したリストを返します. """
return [comic[item] for comic in self.data if comic['title'] == title]
def drop_short_titles(self, titles, min_week):
""" titlesのうち,min_week週以上連載した作品名のリストを返します. """
return [title for title in titles
if len(self.extract_item(title)) >= min_week]
def drop_long_titles(self, titles, max_week):
""" titlesのうち,max_week週以内で終了した作品名のリストを返します. """
return [title for title in titles
if len(self.extract_item(title)) <= max_week]
def find_last_year(self, titles):
""" titlesが掲載された雑誌のうち,最新の年を返します. """
return max([self.extract_item(title, 'year')[-1]
for title in titles])
def find_last_no(self, titles, year):
""" titlesが掲載されたyear年の雑誌のうち,最新の号数を返します. """
return max([self.extract_item(title, 'no')[-1]
for title in titles
if self.extract_item(title, 'year')[-1] == year])
def drop_continued_titles(self, titles, year, no):
""" titlesのうち,year年のno号までに連載が終了した作品名のリストを返します. """
end_titles = []
for title in titles:
last_year = self.extract_item(title, 'year')[-1]
if last_year < year:
end_titles.append(title)
elif last_year == year:
if self.extract_item(title, 'no')[-1] < no:
end_titles.append(title)
return end_titles
def search_title(self, key, titles):
""" titlesのうち,keyを含む作品名のリストを返します. """
return [title for title in titles if key in title]
__init__()︶の動作を補足します.
(一)
self.all_titlesは文字通り全ての作品名を保持します.しかし,self.all_titlesは,明らかに読みきり作品や企画作品を含んでしまっています.
(二)そこで,min_week以上連載した作品をself.serialized_titlesとして抽出します.しかし,self.serialized_titlesは,最新の目次情報の時点で連載中の作品を含んでおり,連載継続期間が不正確です.例えば,﹁鬼滅の刃﹂は現在も連載中の人気作ですが,21週で連載が終了した作品のように見えてしまいます.
(三)そこで,データベースの最新の目次情報の時点で連載が終了した︵と思われれる︶作品のみをself.end_titlesとして抽出します.self.end_titlesが,本分析における全体集合です.
(四)
self.end_titlesのうち,10週以内に終了した作品をself.short_end_titlesとして,11週以上継続した作品をself.long_end_titlesとして抽出します.
4.3 分析
それでは,ComicAnalyzerを使って遊んでみます.
wj = ComicAnalyzer()
まずは,短命作品最新10タイトルの,最初の10週目までの掲載順(worst)をプロットしてみます.値が大きいほど,巻頭付近に掲載されていたことになります.
for title in wj.short_end_titles[-10:]:
plt.plot(wj.extract_item(title)[:50], label=title[:6])
plt.xlabel('Week')
plt.ylabel('Worst')
plt.ylim(0,22)
plt.legend()
 ﹁ギャグマンガ日和﹂などの企画物︵出張作品7︶が入っているのが不満ですが,目次情報だけから除外する手立てはないです.あれ?﹁斉木楠雄﹂って10週以上連載していたんじゃ…?こういうときは,
﹁ギャグマンガ日和﹂などの企画物︵出張作品7︶が入っているのが不満ですが,目次情報だけから除外する手立てはないです.あれ?﹁斉木楠雄﹂って10週以上連載していたんじゃ…?こういうときは,search_title()を使います.
wj.search_title('斉木', wj.all_titles)
# ['超能力者 斉木楠雄のΨ難', '斉木楠雄のΨ難']
len(wj.extract_item('超能力者 斉木楠雄のΨ難'))
# 7
wj.extract_item('超能力者 斉木楠雄のΨ難', 'year'), \
wj.extract_item('超能力者 斉木楠雄のΨ難', 'no')
# ([2011, 2011, 2011, 2011, 2011, 2011, 2011], [22, 27, 29, 33, 42, 43, 50])
len(wj.extract_item('斉木楠雄のΨ難'))
# 201
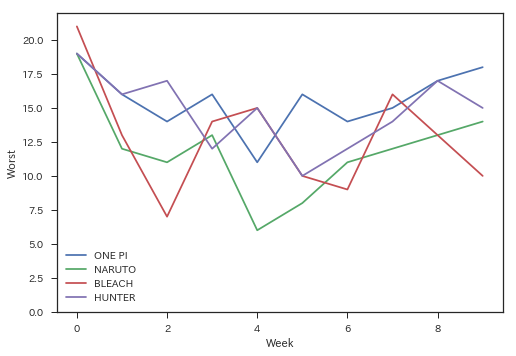
どうやら,「超能力者 斉木楠雄のΨ難」で試験的に7回読み切り掲載したあと,「斉木楠雄のΨ難」の連載を開始したみたいですね(wikipedia). 次は,近年のヒット作(独断)の最初の10話分の掲載順を表示します.
target_titles = ['ONE PIECE', 'NARUTO-ナルト-', 'BLEACH', 'HUNTER×HUNTER']
for title in target_titles:
plt.plot(wj.extract_item(title)[:10], label=title[:6])
plt.xlabel('Week')
plt.ylabel('Worst')
plt.ylim(0,22)
plt.legend()
本記事とは直接関係ありませんが,個人的に気になったので,50話まで掲載順を見てみます.
target_titles = ['ONE PIECE', 'NARUTO-ナルト-', 'BLEACH', 'HUNTER×HUNTER']
for title in target_titles:
plt.plot(wj.extract_item(title)[:100], label=title[:6])
plt.xlabel('Week')
plt.ylabel('Worst')
plt.ylim(0,22)
plt.legend()
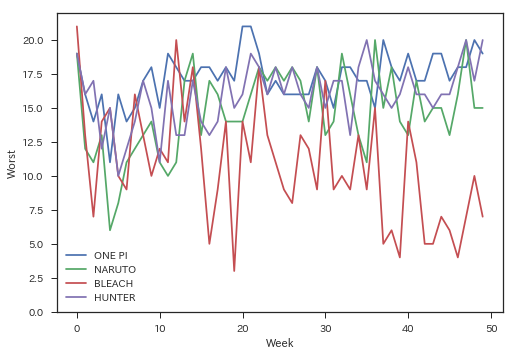
ある程度予想はしてましたが,やっぱりすごいですね.ちなみにですが,extract_item()を使って各話タイトルを取得しながら掲載順を見ると,マンガ好きの方はニヤニヤできます.
wj.extract_item('ONE PIECE', 'subtitle')[:10]
#['1.ROMANCE DAWN―冒険の夜明け―',
# '第2話!! その男"麦わらのルフィ"',
# '第3話 "海賊狩りのゾロ"登場',
# '第4話 海軍大佐"斧手のモーガン"',
# '第5話 "海賊王と大剣豪"',
# '第6話 "1人目"',
# '第7話 "友達"',
# '第8話 "ナミ登場"',
# '第9話 "魔性の女"',
# '第10話 "酒場の一件"']
寄り道しすぎました.seabornのpairplot()で相関分析をやってみます.ここでは,とりあえず2週目から6週目までの掲載順をプロットします.1週目を外したのは,ほとんどの作品は1週目に巻頭に掲載されるためです.なお,同じ座標に複数の点が重なって非常に見づらいので,便宜上ランダムなノイズを加えて見栄えを整えます.
end_data = pd.DataFrame(
[[wj.extract_item(title)[1] + np.random.randn() * .3,
wj.extract_item(title)[2] + np.random.randn() * .3,
wj.extract_item(title)[3] + np.random.randn() * .3,
wj.extract_item(title)[4] + np.random.randn() * .3,
wj.extract_item(title)[5] + np.random.randn() * .3,
'短命作品' if title in wj.short_end_titles else '継続作品']
for title in wj.end_titles])
end_data.columns = ["Worst (week2)", "Worst (week3)", "Worst (week4)",
"Worst (week5)", "Worst (week6)", "Type"]
sns.pairplot(end_data, hue="Type", palette="husl")
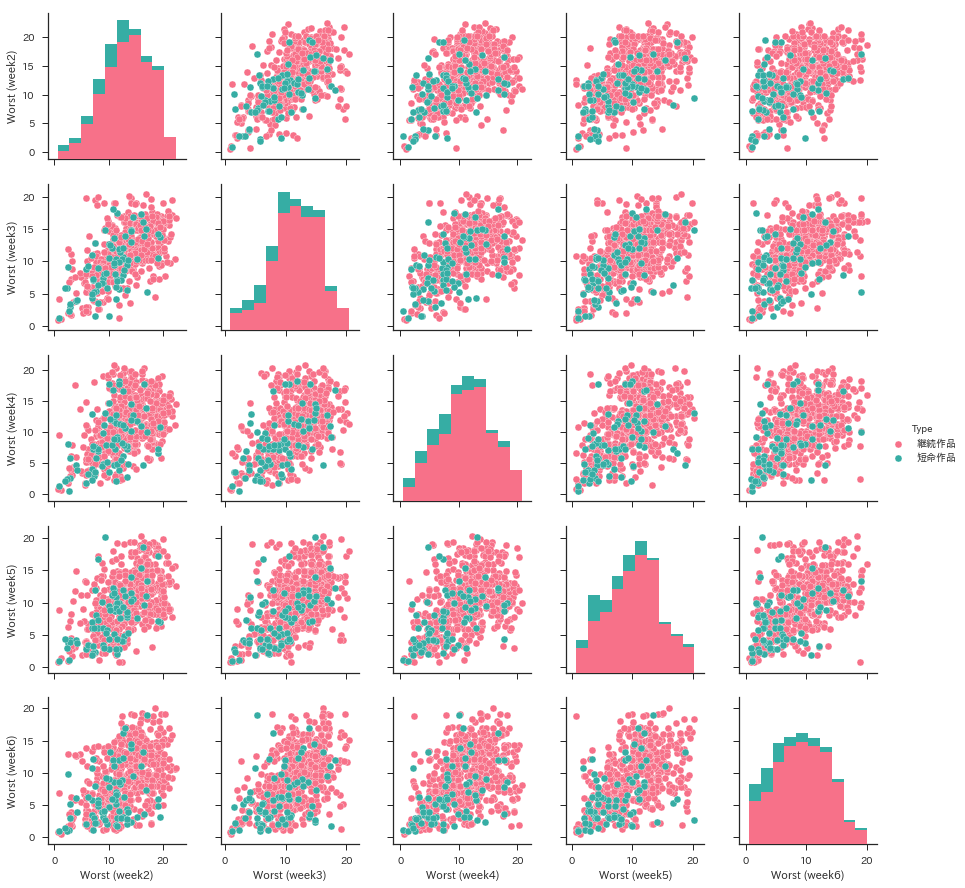 ピンク色は11週以上継続した作品,緑色は10週以内で終了した短命作品です.もっとガッツリ分かれると思っていたのですが,意外と分離が難しそうですね.おそらくですが,﹁ギャグマンガ日和﹂のような企画物や,﹁超能力者 斉木楠雄のΨ難﹂のような試験的な読み切り作品がノイズになっているような気がします.掲載号の連続性で判別しても良いんですが,それだと休載作品と区別できないんですよね….悩ましいです.
とりあえずこのデータのまま,機械学習してみようと思います.
ピンク色は11週以上継続した作品,緑色は10週以内で終了した短命作品です.もっとガッツリ分かれると思っていたのですが,意外と分離が難しそうですね.おそらくですが,﹁ギャグマンガ日和﹂のような企画物や,﹁超能力者 斉木楠雄のΨ難﹂のような試験的な読み切り作品がノイズになっているような気がします.掲載号の連続性で判別しても良いんですが,それだと休載作品と区別できないんですよね….悩ましいです.
とりあえずこのデータのまま,機械学習してみようと思います.
5. おわりに
現実逃避で,気がついたらこんなものを作ってしまいました.次回が本番ですので,お楽しみ頂ければ幸いです.最後までお読み頂き,ありがとうございました!参考文献
本記事の作成にあたっては,以下を参考にさせて頂きました.ありがとうございました!-
日本雑誌協会調べ.2015年10月1日~2016年9月30日における少年向けコミック誌発行部数,男性向けコミック誌発行部数,少女向けコミック誌発行部数,女性向けコミック誌発行部数参照. ↩ 作中では,主に読者アンケートの結果をもとに,掲載順や打ち切り作品を決定していました.以下の記事によると,ジャンプ編集部は﹁必ずしも読者アンケートの結果だけを考慮しているわけではない﹂と,これを否定したようです.﹁ジャンプ﹂編集部がアンケート至上主義の噂を否定も…読者は複雑 ↩ 前述したように,実際には,ジャンプ編集部は様々な要素を考慮して打ち切り作品を決定されています.本記事は,あくまでも一ジャンプファンの妄想として,ご理解頂ければと思います. ↩ 予定です.性能によっては別の手法も検討します. ↩ 2017年4月4日時点. ↩ 当初の予想以上に楽しく遊べたので,二部構成にしました. ↩ ジャンプスクエアで連載中のはずです︵wikipedia︶.なお,2017年4月18日の時点で,データベースにはまだジャンプスクエアの目次情報が登録されていません. ↩