




ツール公開と同時の方が良いのかもしれませんがデモデータが出来ましたので現状報告で上げておきます。
<はじめに>
現状のUTAU音源制作では﹁あいうえお~﹂などと念仏を詠唱するかのようなやり方で音声収録します。このやり方の長所は、効率的に全モーラを網羅できること、それなりに安定した発声の音源になりやすいこと、原音設定がしやすいことだと思います。逆に短所としては、︵個人差はあると思いますが︶、収録していて楽しくない、声の演技表現を入れ辛く棒読みになりがち、といったところかと思います。
この短所を解消する一案として歌声を音源化することが考えられます。端的には好きな歌を歌っているとそれが音源になるというアプローチです。このやり方の長所・短所は既存手法の長所・短所と逆になり、効率が悪い反面楽しさや表現の入れやすさなどのメリットが出てくると期待されます。実際には既存の音源を拡張する形で歌声音源を追加することになるんじゃないかなあと思います︵歌のみではどうしても収録されない音が出てきてしまうので︶。
歌声が音源になるというとSinsyを思い出しますが、類似のアプローチをUTAUのフレームワークでもやってみよう、やったらどんな声になるだろう、といったこと等に今回興味を持ってテストしています。大元のきっかけは8月にアシスPさんとtwitterでその辺のやり取りを少ししたことだったと記憶しています。
<Fransing>
歌声wavを音源化するにはwav分割ツールが必要ですのでFransingというツールを作ってみています。このツールを使って下図の流れで音源を作ります。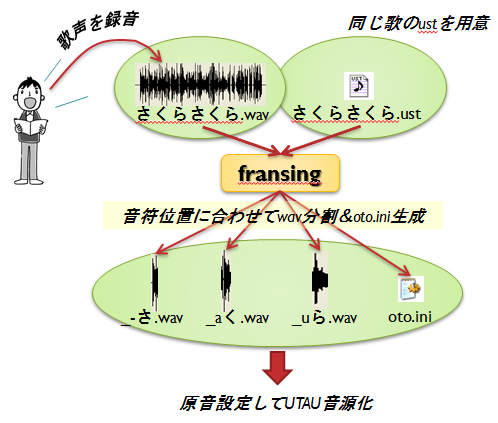
歌のwavとそのustをfransingに入力すると各音符位置に従ってwavが分割されます。oto.iniも生成しますが現状では全面的に手修正が必要と思って下さい。私が試したときは、発声タイミングと音符位置がぴったりのことはあまりなく、ほとんどの音がばらつくようでした。また既存の連続音収録のように各音の長さが均一でないので、その点でもいつもより神経を使う印象でした︵私はsetParamの範囲指定再生、発声タイミング試聴、スペクトルを頼りにしました︶。原音設定師さんの腕の奮い所かもしれません。
<テスト>
ツールがひとまず動くようになったのでどんな音になるのかテストしてみました。テストにあたって、梟音キリィ等の中の人をされているCaparo Ululaさんから﹁耳のあるロボットの唄﹂の一番を3パターン(normal、 strange、weaker)の歌い方で歌ったwavを頂きました。ありがとうございます。
これらのwavを使って下記2種類のテストを行いました。
まず、以下の音デモ3つは、歌声wavをfransingに通して分割し、原音設定を手修正し、再度﹁耳~﹂を歌わせたものです。UTAUでの調声は﹁おま☆かせ﹂のみ、合成エンジンはTIPS、リバーブなどのエフェクトは未使用です。
fransing demo︵クローズドテスト︶bynwp8861
なお、このテストでは元歌唱で歌った歌を再度歌わせているので本来の環境よりも有利な条件下での結果といえます。つまり機械学習系でいうところのクローズドな評価であり、理想的な状態であればこの品質にまで近づける、といった目安になります︵通常はこれより品質が下がります︶。
私感ではweakerは人間っぽいなあと思いました︵思わずオケをスズナリさん版にしてしまいました︶。normalとstrangeではうまく合成できない音もありじゃじゃ馬音源"になりそうでもありますが、どちらも歌い方のクセや表現の違いは聞き分けられそうだなあと思いました。
次のテストです。
実環境下でテストするには﹁耳~﹂とは別の歌を歌わせる必要があります︵機械学習系でいうところのオープンな評価︶。しかし﹁耳~﹂の一番のみではデータが少なく簡単にテストできません︵一番のみで178モーラのデータが収集されますが中には重複もあります︶。
そのため連続音音源としてのテストではないのですが、折角なのでれんたんじゅつ的な原音設定をして単独音音源も作ってみました。単独音では51種類のモーラを使えるようになったので、それらのモーラのみで強引に歌詞らしいものを作って別の曲を歌わせてみました。 fransing demo︵オープンテスト︶bynwp8861
クローズドに比べるとやはり品質は下がっています。合成がうまくいっていない音で同じ音が複数選べる場合は最良に聴こえるものを選びましたが不自然さが目立ちます。ここでも総合的にはweakerがアラが少なめで良さそうです。抑揚を抑える表現なので安定するのかもしれません。normalとstrangeについてもクローズド同様"じゃじゃ馬音源"感がありますが何だか生き生きとして歌っている感じがするのが良いなと思いました。
<まとめ>
以上が現状の結果です。今回の結果はまだ一つ目なので、他の歌を音源にしたらまた違う結果が出て面白いかもしれません。また例えば、もっと遅い曲で音源化すれば"じゃじゃ馬音源"にならないんじゃないか︵﹁耳~﹂は180BPMです︶とか、原音設定次第でもう少し良くなるんじゃないか、長い音符の声を優先して使うと良いのかなとか、考えるところは他にもあります。最終結果ではないのでこれを聴いて次はどうしようかなあと考えたりしています。
fransingはあと少しいじりたい箇所があるので修正次第アップロードしたいと思います。ただ、今はsetParamの方をいじっているのでその後の作業になるかもしれません。どちらも近日中に上げられたら良いなあと思っています。
それではひとまずこの辺で。。
現状のUTAU音源制作では﹁あいうえお~﹂などと念仏を詠唱するかのようなやり方で音声収録します。このやり方の長所は、効率的に全モーラを網羅できること、それなりに安定した発声の音源になりやすいこと、原音設定がしやすいことだと思います。逆に短所としては、︵個人差はあると思いますが︶、収録していて楽しくない、声の演技表現を入れ辛く棒読みになりがち、といったところかと思います。
この短所を解消する一案として歌声を音源化することが考えられます。端的には好きな歌を歌っているとそれが音源になるというアプローチです。このやり方の長所・短所は既存手法の長所・短所と逆になり、効率が悪い反面楽しさや表現の入れやすさなどのメリットが出てくると期待されます。実際には既存の音源を拡張する形で歌声音源を追加することになるんじゃないかなあと思います︵歌のみではどうしても収録されない音が出てきてしまうので︶。
歌声が音源になるというとSinsyを思い出しますが、類似のアプローチをUTAUのフレームワークでもやってみよう、やったらどんな声になるだろう、といったこと等に今回興味を持ってテストしています。大元のきっかけは8月にアシスPさんとtwitterでその辺のやり取りを少ししたことだったと記憶しています。
歌声wavを音源化するにはwav分割ツールが必要ですのでFransingというツールを作ってみています。このツールを使って下図の流れで音源を作ります。
歌のwavとそのustをfransingに入力すると各音符位置に従ってwavが分割されます。oto.iniも生成しますが現状では全面的に手修正が必要と思って下さい。私が試したときは、発声タイミングと音符位置がぴったりのことはあまりなく、ほとんどの音がばらつくようでした。また既存の連続音収録のように各音の長さが均一でないので、その点でもいつもより神経を使う印象でした︵私はsetParamの範囲指定再生、発声タイミング試聴、スペクトルを頼りにしました︶。原音設定師さんの腕の奮い所かもしれません。
ツールがひとまず動くようになったのでどんな音になるのかテストしてみました。テストにあたって、梟音キリィ等の中の人をされているCaparo Ululaさんから﹁耳のあるロボットの唄﹂の一番を3パターン(normal、 strange、weaker)の歌い方で歌ったwavを頂きました。ありがとうございます。
これらのwavを使って下記2種類のテストを行いました。
まず、以下の音デモ3つは、歌声wavをfransingに通して分割し、原音設定を手修正し、再度﹁耳~﹂を歌わせたものです。UTAUでの調声は﹁おま☆かせ﹂のみ、合成エンジンはTIPS、リバーブなどのエフェクトは未使用です。
fransing demo︵クローズドテスト︶bynwp8861
なお、このテストでは元歌唱で歌った歌を再度歌わせているので本来の環境よりも有利な条件下での結果といえます。つまり機械学習系でいうところのクローズドな評価であり、理想的な状態であればこの品質にまで近づける、といった目安になります︵通常はこれより品質が下がります︶。
私感ではweakerは人間っぽいなあと思いました︵思わずオケをスズナリさん版にしてしまいました︶。normalとstrangeではうまく合成できない音もありじゃじゃ馬音源"になりそうでもありますが、どちらも歌い方のクセや表現の違いは聞き分けられそうだなあと思いました。
次のテストです。
実環境下でテストするには﹁耳~﹂とは別の歌を歌わせる必要があります︵機械学習系でいうところのオープンな評価︶。しかし﹁耳~﹂の一番のみではデータが少なく簡単にテストできません︵一番のみで178モーラのデータが収集されますが中には重複もあります︶。
そのため連続音音源としてのテストではないのですが、折角なのでれんたんじゅつ的な原音設定をして単独音音源も作ってみました。単独音では51種類のモーラを使えるようになったので、それらのモーラのみで強引に歌詞らしいものを作って別の曲を歌わせてみました。 fransing demo︵オープンテスト︶bynwp8861
クローズドに比べるとやはり品質は下がっています。合成がうまくいっていない音で同じ音が複数選べる場合は最良に聴こえるものを選びましたが不自然さが目立ちます。ここでも総合的にはweakerがアラが少なめで良さそうです。抑揚を抑える表現なので安定するのかもしれません。normalとstrangeについてもクローズド同様"じゃじゃ馬音源"感がありますが何だか生き生きとして歌っている感じがするのが良いなと思いました。
以上が現状の結果です。今回の結果はまだ一つ目なので、他の歌を音源にしたらまた違う結果が出て面白いかもしれません。また例えば、もっと遅い曲で音源化すれば"じゃじゃ馬音源"にならないんじゃないか︵﹁耳~﹂は180BPMです︶とか、原音設定次第でもう少し良くなるんじゃないか、長い音符の声を優先して使うと良いのかなとか、考えるところは他にもあります。最終結果ではないのでこれを聴いて次はどうしようかなあと考えたりしています。
fransingはあと少しいじりたい箇所があるので修正次第アップロードしたいと思います。ただ、今はsetParamの方をいじっているのでその後の作業になるかもしれません。どちらも近日中に上げられたら良いなあと思っています。
それではひとまずこの辺で。。