過剰適合
この記事は英語版の対応するページを翻訳することにより充実させることができます。(2024年5月) 翻訳前に重要な指示を読むには右にある[表示]をクリックしてください。
●英語版記事を日本語へ機械翻訳したバージョン︵Google翻訳︶。
●万が一翻訳の手がかりとして機械翻訳を用いた場合、翻訳者は必ず翻訳元原文を参照して機械翻訳の誤りを訂正し、正確な翻訳にしなければなりません。これが成されていない場合、記事は削除の方針G-3に基づき、削除される可能性があります。
●信頼性が低いまたは低品質な文章を翻訳しないでください。もし可能ならば、文章を他言語版記事に示された文献で正しいかどうかを確認してください。
●履歴継承を行うため、要約欄に翻訳元となった記事のページ名・版について記述する必要があります。記述方法については、Wikipedia:翻訳のガイドライン#要約欄への記入を参照ください。
●翻訳後、 {{翻訳告知|en|Overfitting|…}}をノートに追加することもできます。
●Wikipedia:翻訳のガイドラインに、より詳細な翻訳の手順・指針についての説明があります。
|
過剰適合︵かじょうてきごう、英: overfitting︶や過適合︵かてきごう︶や過学習︵かがくしゅう、英: overtraining︶とは、統計学や機械学習において、訓練データに対して学習されているが、未知データ︵テストデータ︶に対しては適合できていない、汎化できていない状態を指す。汎化能力の不足に起因する。

ノイズのある、ほぼ線形なデータは、一次関数にも多項式関数にも適合 する。多項式関数は各データポイントを通過し、一次関数は必ずしもデータポイントを通過しないが、端の方で大きな変化が生じることがないため、一次関数の方がよりよい適合であると言える。回帰曲線を使ってデータを外挿した場合、過剰適合であれば悪い結果となる。
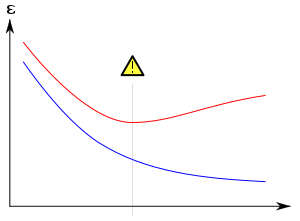
教師あり学習︵ニューラルネットワークなど︶における過剰適合。訓練 時のエラーを青、評価時のエラーを赤で示している。訓練時のエラーが減少しているのに、評価時のエラーが増えている場合、過剰適合が起きている可能性がある。
その原因の一つとして、統計モデルへの適合の媒介変数が多すぎる等、訓練データの個数に比べて、モデルが複雑で自由度が高すぎることがある。不合理で誤ったモデルは、入手可能なデータに比較して複雑すぎる場合、完全に適合することがある。
対義語は過少適合︵かしょうてきごう、英: underfitting︶や過小学習︵かしょうがくしゅう、英: undertraining︶。


機械学習
編集
機械学習の分野では過学習︵overtraining︶とも呼ばれる。過剰適合の概念は機械学習でも重要である。通常、学習アルゴリズムは一連の訓練データを使って訓練される。つまり、典型的な入力データとその際の既知の出力結果を与える。学習者はそれによって、訓練データでは示されなかった他の例についても正しい出力を返すことができるようになると期待される。しかし、学習期間が長すぎたり、訓練データが典型的なものでなかった場合、学習者は訓練データの特定のランダムな︵本来学習させたい特徴とは無関係な︶特徴にまで適合してしまう。このような過剰適合の過程では、訓練データについての性能は向上するが、それ以外のデータでは逆に結果が悪くなる。
交差検証
編集詳細は「交差検証」を参照
過剰適合の回避方法
編集「偏りと分散」も参照
正則化
編集詳細は「正則化」を参照
機械学習や統計学において、媒介変数を減らすのではなく、誤差関数に正則化項を追加して、モデルの複雑度・自由度に抑制を加え、過学習を防ぐ方法がある。L2 正則化や L1 正則化などがある。
サポートベクターマシンにおいては、媒介変数︵パラメータ︶を減らすのではなく、マージンを最大化することにより、過学習を防いでいて、これも、L2 正則化と同じような手法に基づいている。
早期打ち切り
編集早期打ち切り(early stopping)とは、学習の反復において、訓練データと評価データの両方の評価値を監視し、評価データでの評価値が悪化し始める所で学習を早期に打ち切る方法。
参考文献
編集- Tetko, I. V.; Livingstone, D. J.; Luik, A. I. (1995). “Neural network studies. 1. Comparison of Overfitting and Overtraining”. J. Chem. Inf. Comput. Sci. 35 (5): 826–833. doi:10.1021/ci00027a006.